Fission Kafka Sample
Categories:
Introduction
The open-source Apache Kafka is one of the most popular distributed Stream Processing platforms used for building real time streaming data pipelines and applications. To learn more about Kafka visit the Kafka documentation.
Most serverless functions are triggered by an event, and these in turn may trigger consequent events, which could invoke further functions. This makes Kafka - which acts as a event broker - a natural companion to a Functions-as-a-Service (FaaS) platform such as Fission.
Fission already supports nats-streaming and azure-storage-queue, with Kafka integration planned for the 0.11 release. Using this Kafka integration we can build a quick demo and show the power of serverless functions for stream processing use cases.
To follow along the tutorial, first install Fission on a Kubernetes cluster of your choice.
Use Case
This use case is inspired by the demo of IoT platform for a shipping company built by Yugabyte. The fleet of vehicles report vital data every fixed duration to a central API. The API stores the data in Kafka, which is then processed by the workers while storing the analysis results in a database. We use the same concept with Fission functions and Kafka as the event platform.
Architecture
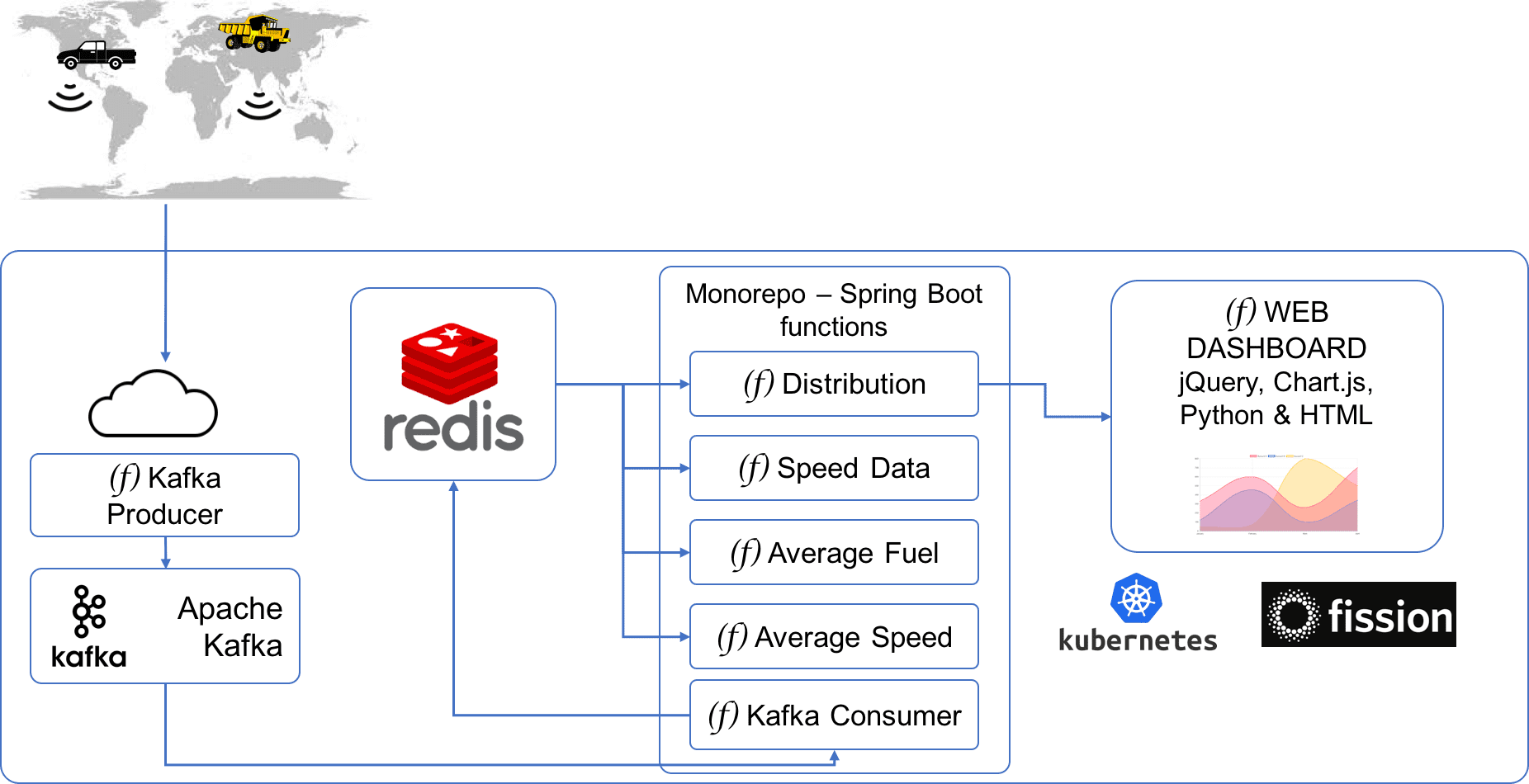
The above diagram represents the architecture of the IoT platform. All the Serverless functions are written in Fission’s JVM environment.
-
The Kafka Producer is a Fission function which can be triggered by a time trigger every few seconds/minutes to simulate incoming data from the fleet. This function generates random 100 records on every invocation. Each record has the following fields of for each vehicle in the fleet:
- Vehicle ID
- Vehicle Type
- Route ID
- Latitude
- Speed
- Fuel Level
- Time of record
-
Apache Kafka stores the events as they are pushed by the Producer.
-
For every event in the Kafka, a function is triggered - which is a Consumer function. Because of Fission’s integration with Kafka, the function automatically gets a message body and does not require you to write any Kafka consumer code. The Consumer persists this message in Redis.
-
Redis stores the last 10K records in each category as they are pushed by the Kafka Consumer.
-
There are four Consumer functions - each fetching data from Redis and exposing it on a REST endpoint. These four functions and the Kafka consumer are in the same repo/JAR and are deployed using the same artifact.
-
Finally, one of the interesting functions is a Dashboard function. This function is pure HTML & JavaScript which is served by a simple Python program.
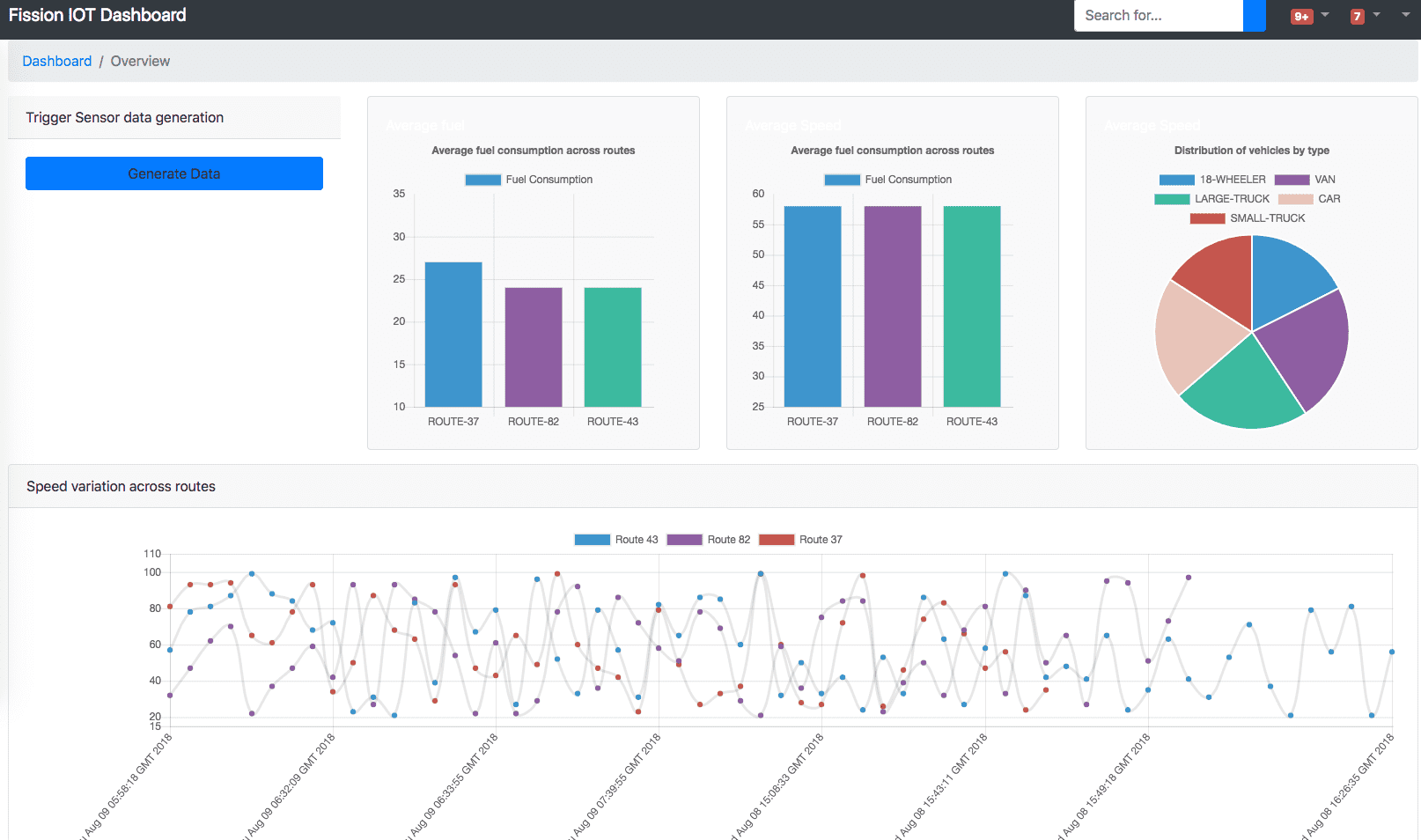
Dashboard
Once you setup required components (explained here) and deploy the functions, you will see a dashboard like below. Based on the data present in your system, the look and feel will vary.
Try it out
The demo and setup instructions are at https://github.com/fission/fission-kafka-sample so you can try it out yourself!
Follow us on Twitter for more updates! @fissionio
Author: